| Pages:
1
..
11
12
13
14
15
..
22 |
Zombie
Forum Hillbilly
Posts: 1700
Registered: 13-1-2015
Location: Florida PanHandle
Member Is Offline
Mood: I just don't know...
|
|
Good for you Delta!!!!!!!
I'm always gonna be a "billy"
I should'a thought that thru some...
They tried to have me "put to sleep" so I came back to return the favor.
Zom.
|
|
|
deltaH
Dangerous source of unreferenced speculation
Posts: 1663
Registered: 30-9-2013
Location: South Africa
Member Is Offline
Mood: Heavily protonated
|
|
Thank you, thank you. Don't worry zombie, it's a fun reminder to all of us of the thumping thumper thread.
|
|
|
Zombie
Forum Hillbilly
Posts: 1700
Registered: 13-1-2015
Location: Florida PanHandle
Member Is Offline
Mood: I just don't know...
|
|
It did sort of set the tone, and introduced my "personality"?.?.?
It's all good. Kudos!
They tried to have me "put to sleep" so I came back to return the favor.
Zom.
|
|
|
blogfast25
International Hazard
Posts: 10562
Registered: 3-2-2008
Location: Neverland
Member Is Offline
Mood: No Mood
|
|
Quote: Originally posted by deltaH  | This is much of a muchness. Just pyrolyse the beans in a tin on the coals of a barbie and be done with it. Simple, no mess, no fuss. Don't forget to
punch a small hole in the top of the tin for the volatiles to escape. You can then impregnate the charred beans with catalyst to your heart's content
without anything going awry.
|
I'm a great fan of sacrificing quantity for better control. Something like the catalysed pyrolysis of dried beans carried out on a 100 g sample, with
careful capture of any NO2 could teach us more than less controlled, larger trials.
Try and be aspirational? 
[Edited on 6-3-2015 by blogfast25]
|
|
|
Zombie
Forum Hillbilly
Posts: 1700
Registered: 13-1-2015
Location: Florida PanHandle
Member Is Offline
Mood: I just don't know...
|
|
Quote: Originally posted by Zombie
I'm always gonna be a "billy"
Try and be aspirational?
I'm going to buy a real friend today.
They tried to have me "put to sleep" so I came back to return the favor.
Zom.
|
|
|
CuReUS
National Hazard
Posts: 928
Registered: 9-9-2014
Member Is Offline
Mood: No Mood
|
|
zombie's magnetron arc is amazing,even better than WGTR'S neodymium one
but I was wondering,why not use the arc to make things other than nitric acid,like HCN or ketene ?
acetylene +N2>(arc)>>2HCN
|
|
|
aga
Forum Drunkard
Posts: 7030
Registered: 25-3-2014
Member Is Offline
|
|
One small difference: WGTR's is Real.
[Edited on 12-3-2015 by aga]
|
|
|
Zombie
Forum Hillbilly
Posts: 1700
Registered: 13-1-2015
Location: Florida PanHandle
Member Is Offline
Mood: I just don't know...
|
|
What on earth are you talking about?
I have burned more sh#t using magnatrons than any other plug in the wall device I can think of.
Set one of these inside the end of a pipe, and use resistance controlled SSR, as a controller.
You can set it to burn paper or just about melt the pipe.
Burning Bean Dust is a breaze.
[Edited on 3-12-2015 by Zombie]
They tried to have me "put to sleep" so I came back to return the favor.
Zom.
|
|
|
aga
Forum Drunkard
Posts: 7030
Registered: 25-3-2014
Member Is Offline
|
|
Cool !
Show us the photos and maybe win the challenge !
Edit:
Just collect the gas, and job done.
Hmm. Would the magnetron require/generate > 230V *1.41 ?
[Edited on 12-3-2015 by aga]
|
|
|
Zombie
Forum Hillbilly
Posts: 1700
Registered: 13-1-2015
Location: Florida PanHandle
Member Is Offline
Mood: I just don't know...
|
|
Here's a couple of Utube vids that explain it.
There are two ways to control the output.
The first (better) is to interrupt the +5volt filament lead with the SSR. This limits the amount of electrons produced, and lowers the output power.
The second method is to interrupt the line voltage in (110V AC) with the SSR.
The issue there is the power output is not as easy to regulate. You go from nothing to near full power in an instant.
The video will explain why this happens.
I would build the entire magnatron, and at least 1 foot of 2 inch diameter pipe into a concrete insulator similar to a forced air furnace. It will get
that hot if you allow it to. A cooling fan will go a long way to making this work long term.
https://www.youtube.com/watch?v=qT6EmMkKevY
https://www.youtube.com/watch?v=I2k2g00onL0
[Edited on 3-13-2015 by Zombie]
[Edited on 3-13-2015 by Zombie]
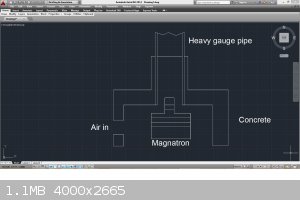
I just came across this article...
http://www.google.com/patents/WO2013141725A1?cl=en
[Edited on 3-13-2015 by Zombie]
[Edited on 3-13-2015 by Zombie]
They tried to have me "put to sleep" so I came back to return the favor.
Zom.
|
|
|
CuReUS
National Hazard
Posts: 928
Registered: 9-9-2014
Member Is Offline
Mood: No Mood
|
|
| Quote: Originally posted by Zombie |
I have burned more sh#t using magnatrons than any other plug in the wall device I can think of.
Burning Bean Dust is a breaze.
|
No,You don't understand.I meant putting the magnetron arc in WGTR's setup instead of the neodymium one,not using it to burn beans
I thought that idea crashed and burned long ago
|
|
|
j_sum1
Administrator
Posts: 6251
Registered: 4-10-2014
Location: Unmoved
Member Is Offline
Mood: Organised
|
|
Hey. Burning beans hasn't crashed. They just haven't burned yet.
Maybe this weekend.
|
|
|
Zombie
Forum Hillbilly
Posts: 1700
Registered: 13-1-2015
Location: Florida PanHandle
Member Is Offline
Mood: I just don't know...
|
|
| Quote: Originally posted by CuReUS | | Quote: Originally posted by Zombie |
I have burned more sh#t using magnatrons than any other plug in the wall device I can think of.
Burning Bean Dust is a breaze.
|
No,You don't understand.I meant putting the magnetron arc in WGTR's setup instead of the neodymium one,not using it to burn beans
I thought that idea crashed and burned long ago |
I don't know what WTGR's neodymium thing is.
I'm sure you get it! 
They tried to have me "put to sleep" so I came back to return the favor.
Zom.
|
|
|
WGTR
National Hazard
Posts: 971
Registered: 29-9-2013
Location: Online
Member Is Offline
Mood: Outline
|
|
Adsorption and Desorption of Dilute NO2 on Silica Gel
This is potentially important for anyone generating a dilute stream of NO2, regardless of how it is made. A dilute feed of (ideally) dry
NO2 can be pumped through silica gel (indicating, in this case). Upon saturation, the beads can be heated up, causing them to desorb the
concentrated NO2.
The following video is my "neodymium thingy" generating some NO2, as described in my earlier posts. NO is generated in the small arc
chamber, which then oxidizes to NO2 in the bottle. The dilute NO2 is then adsorbed onto a column of indicating silica gel. The
bubbler in the test tube functions just as a flow meter of sorts. All of the NO2 is adsorbed before it gets that far.
Attachment: NO2_Adsorption.avi (9.6MB)
This file has been downloaded 1045 times
After placing the saturated beads into a sealed test tube, I heated the bottom with a heat gun to drive off some NO2:

I didn't heat the beads very much, because I didn't want to pop the stopper off the tube. I had to be careful doing this. In other words, the
picture doesn't demonstrate very efficient desorption. Some moisture was adsorbed from the gas stream, shown by the condensation under the test tube
stopper.
|
|
|
Zombie
Forum Hillbilly
Posts: 1700
Registered: 13-1-2015
Location: Florida PanHandle
Member Is Offline
Mood: I just don't know...
|
|
That is just insanely creative.
Have you managed to create any Nitric acid from this yet?
They tried to have me "put to sleep" so I came back to return the favor.
Zom.
|
|
|
WGTR
National Hazard
Posts: 971
Registered: 29-9-2013
Location: Online
Member Is Offline
Mood: Outline
|
|
Small amounts. Right now I'm just trying to figure out what I'm doing. This particular setup is small, and might be able to make 1 ml of
concentrated acid per day. The arc chamber itself is only using about 5W average power.
I'll probably add a moisture adsorption column right before the arc chamber, to keep the adsorbed NO2 dry...not that it matters very much.
To scale this up, I'm planning on utilizing the tube furnace that I put together here:
https://www.sciencemadness.org/whisper/viewthread.php?tid=55...
When cool, silica gel in the tube could adsorb the dilute NO2. When heated, concentrated NO2 can be flushed out, regenerating
the column. I didn't mention this previously, but it is much easier to make nitric acid from concentrated NO2 than it is from the diluted
variety. NO oxidizes much faster to NO2 when it is concentrated. That's one reason I'm doing it this way. Another reason is that the
creation of NO2 and the formation of nitric acid do not have to happen at the same time. Theoretically a bottle full of silica gel could
store concentrated NO2 for a long time.
As an aside, only NO2 is adsorbed in the silica gel, not NO. This can be a useful way of purifying NO.
|
|
|
deltaH
Dangerous source of unreferenced speculation
Posts: 1663
Registered: 30-9-2013
Location: South Africa
Member Is Offline
Mood: Heavily protonated
|
|
That's very smart WGTR, genius. Well done indeed!
|
|
|
aga
Forum Drunkard
Posts: 7030
Registered: 25-3-2014
Member Is Offline
|
|
Positive proof that chasing insane ideas can lead to insanely wonderful discoveries.
BRAVO WGTR !
|
|
|
deltaH
Dangerous source of unreferenced speculation
Posts: 1663
Registered: 30-9-2013
Location: South Africa
Member Is Offline
Mood: Heavily protonated
|
|
Can one not add the NO2 loaded silica straight to water or even better, dilute H2O2? If you had enough, then eluting through a short column could
yield pretty strong acid perhaps.
|
|
|
WGTR
National Hazard
Posts: 971
Registered: 29-9-2013
Location: Online
Member Is Offline
Mood: Outline
|
|
Well, you know what they say...every family should have at least three children. That way if one of them turns out to be a genius, the other two can
support him!
Thanks for the compliments all three of you. I do, however, stand on the shoulders of people much smarter than I am. I hope not to imply otherwise.
The idea of NO2 adsorption onto silica gel is not a new one. Here is the patent that I borrowed the idea from:
Attachment: US2578674.pdf (1.8MB)
This file has been downloaded 1084 times
| Quote: Originally posted by deltaH | | Can one not add the NO2 loaded silica straight to water or even better, dilute H2O2? If you had enough, then eluting through a short column could
yield pretty strong acid perhaps. |
Those are interesting ideas. The first one would work if the gel is reusable, and doesn't disintegrate in the process. The second idea would work if
one doesn't mind buying the peroxide from the grocery store.
Silica gel does a lot of interesting things to different substances. I don't claim to know much about it right now. Depending on whether it holds on
better to water or nitric acid, it may be possible to concentrate it by passing nitric acid vapors over it. I seem to remember reading somewhere that
it is very difficult to get all the nitric acid out of silica gel, even by rinsing it with water. I'll have to double-check that, though.
I'm starting school again tomorrow morning. That means that I'll be quite busy again, unfortunately. I cleaned out the fume hood a few hours ago to
prepare for tomorrow's work. This project was carefully disassembled and put in the cabinet, where it will rest for hopefully not very long. Have a
good week everybody.
|
|
|
CuReUS
National Hazard
Posts: 928
Registered: 9-9-2014
Member Is Offline
Mood: No Mood
|
|
| Quote: | | if one doesn't mind buying the peroxide from the grocery store |
50% H2O2 can be made by electrolysing dilute H2SO4
WGTR,what about replacing that neodymium disk with a magnetron arc,or is it jus too dangerous ?
also,no one paid attention to this
| Quote: | but I was wondering,why not use the arc to make things other than nitric acid,like HCN or ketene ?
acetylene +N2>(arc)>>2HCN |
|
|
|
aga
Forum Drunkard
Posts: 7030
Registered: 25-3-2014
Member Is Offline
|
|
Probably because the thread is about making HNO3.
Do some experiments with arcing and see what else it can be applied to.
|
|
|
WGTR
National Hazard
Posts: 971
Registered: 29-9-2013
Location: Online
Member Is Offline
Mood: Outline
|
|
| Quote: Originally posted by CuReUS |
WGTR,what about replacing that neodymium disk with a magnetron arc,or is it jus too dangerous ?
also,no one paid attention to this
| Quote: | but I was wondering,why not use the arc to make things other than nitric acid,like HCN or ketene ?
acetylene +N2>(arc)>>2HCN |
|
Since you ask, frankly, the magnetron idea frightens me, about as much as using a high-powered laser. One must be careful of any unintended
reflections of energy in both cases.
I've tried to design the arc chamber such that it doesn't require a high voltage, high current power supply. I've separated the high voltage and high
current functions into separate power supplies, such that there is no current behind the high voltage igniter, and there is relatively low voltage
driving the high current arc. I actually got across the high voltage ignition coil. It was unpleasant, but still reasonably safe for a healthy
individual.
This type of system is not intended to be something that a trained squirrel can operate. At the same time, I figure that some 12-year-olds somewhere
may try building this. I'm trying to be careful not to give them a way to inadvertently kill themselves.
When I work with cyanides, I go to great lengths to avoid making HCN. Any time I have tried making cyanides, I did so without creating HCN
itself. Ketene is something I've never tried making. It's hazardous, and I don't really need acetic anhydride for anything.
|
|
|
aga
Forum Drunkard
Posts: 7030
Registered: 25-3-2014
Member Is Offline
|
|
Funny how people with Common Sense tend to live longer ...
|
|
|
Zombie
Forum Hillbilly
Posts: 1700
Registered: 13-1-2015
Location: Florida PanHandle
Member Is Offline
Mood: I just don't know...
|
|
Languishing in misery ... 
They tried to have me "put to sleep" so I came back to return the favor.
Zom.
|
|
|
| Pages:
1
..
11
12
13
14
15
..
22 |